
article
New global entities model: How LivePerson is improving named entity recognition for better bots
A new BERT-based model will recognize global entities in conversational messages with better precision and recall

October 06, 2022 • 11 minutes

At LivePerson, our goal is to help you understand your customers and provide them with a Curiously Human™ experience that makes them love your brand. Artificial intelligence makes this customer engagement scalable, but it’s only possible using natural language understanding and named entity recognition.
Let’s go behind the scenes to discuss how an AI chatbot can converse in an accurate, helpful way — and how our data scientists are working to improve this challenging task.
Entities and named entity recognition
Entities are the things, and their attributes, referred to in customer conversations. More formally, a named entity is a set of elements that is important to understanding raw text, but is not necessarily related to the intent of the raw text. In general, entities can be swapped while preserving the general intent of the text.
Often, named entities are the nouns and adjectives in a sentence, but they can be almost any part of speech. LivePerson’s entity definitions are flexible, meaning entities are whatever you want to capture from your customer conversations. Some examples:
In other words, entities enable artificial intelligence to understand text at a deeper level. Without entities, artificial intelligence would know someone wants to buy something, but wouldn’t know what they want to buy, or where they want it delivered, or how they want to pay. That’s why named entity recognition, a natural language processing technique for automatically identifying entities in a sentence and classifying them into pre-defined categories, is so important.
How to recognize entities
LivePerson offers three approaches for entity recognition and management. Like everything, these approaches offer different trade-offs.
List entities: List entities represent a list of entity values to an entity type. For example, a fast food restaurant might have a sandwich entity represented by a list of three entity values: “Reuben,” “Veggie,” and “Grilled Cheese.” Generally, list entities are a good choice when there are a limited number of potential entity values that can be easily enumerated within a list. However, when hundreds or even thousands of values are possible, a Regex entity is a better choice.
Regex entities: Regex entities are defined using regular expressions. They allow matching patterns, so there is no need to list each possibility, nor is there a limit on the potential list of entity values that can be recognized. For example, if a serial number is always “a,” “b,” or “c” followed by 5 digits and the letter “x,” then the regular expression “[a|b|c]\d{5}x” would match all values of that entity. Regex entities can require careful consideration to not over-match. For example, if a hotel room number were a three- or four-digit number, ”\d{3,4}” would find all the room numbers, but it would also match the first four digits of a zip code. While list and regex entities are simple to use, they require careful design and maintenance to be successful. Towards mitigating this, machine learning has been found to be effective at recognizing entities.
Machine-learning entities: Machine-learning entities are recognized using a model that is trained on large amounts of data that has been labeled with the desired entities. Machine learning is most useful for recognizing entities that cannot easily be enumerated or defined by a format. In other words, machine learning can detect entities where list and regex entities won’t work. For instance, it can handle city names, where a list would be prohibitively large and there is no set format.
More importantly, machine learning takes advantage of context. For example, machine learning will recognize monetary values like “fifteen grand” in this context: “That car will run you about fifteen grand.” But in the context of “Please deliver it on November fifteen grand pianos are awesome,” it will recognize “November fifteen” as a date and ignore “grand.” In general, machine learning is more able to handle open-ended sets like city names and unanticipated presentations like “forty-four” for 44.
Global vs. custom entities
Before we move on to how LivePerson is improving named entity recognition for more capable bots, it’s important to explain the difference between custom and global entities:
Global entities are provided universally by the LivePerson platform. They are recognized by a machine learning model, and include generally useful things like people’s names, numbers, dates, times, and more. This is where LivePerson’s update is focused.
On the other hand, custom entities are brand specific and are either list or regex entities. Custom entities can be whatever a brand needs to recognize in their customer conversations — product names, sizes, colors, seat classes on a train, attributes of a service, or anything else.
LivePerson’s global entities model update
LivePerson is releasing a new BERT-based global entity management model — developed in-house — to recognize global entities in conversational messages. This delivers four main improvements:
- It recognizes new entity types.
- The model recognizes entities with better precision and recall.
- We’ll be able to add new entity types as we discover new use cases.
- The model can be optimized more effectively.
BERT is a powerful new deep neural network model that has rapidly gained popularity over the past few years. BERT stands for Bidirectional Encoder Representations from Transformers, which is a lot to unpack. In essence:
- “Transformer” means that BERT looks at the whole text at once. Context is key and BERT uses “self attention,” which means the model itself develops a sense of the significance of each part of a particular string of text.
- “Bidirectional” means BERT’s search for significance in a string of text can work backwards and forwards, enabling context to play a large role in BERT’s success.
BERT is a general purpose machine-learning tool. In developing a BERT-based global entity model, we gave it a large quantity of high-quality training data. LivePerson’s expert taxonomists reviewed examples taken from billions of messages to assemble the best, most representative training phrases to teach the model how to recognize named entities. The resulting BERT model’s dramatically superior performance allowed us to do two things at once: add new entity types and significantly improve performance.
1 – Supporting new global entity types
With the new model, we’re able to support the following global entity types:
- PERSON NAME – the name of a person including the title such as Dr. Hill
- ORGANIZATION – the name of an organization when mentioned in isolation and not in the context of a product as a product manufacturer
- MONEY – a currency or price value including the currency indicator (symbol or descriptive name)
- QUANTITY – a number denoting quantity (one, two, three, 1, 2, 3, etc.), as opposed to an ordinal number (first, second, third, etc.)
- DATE – the calendar day of the month or year as specified by a spelled out or numerical representation. The date can be a non-specific reference.
- TIME – time in a day or reference to a period of time such as “afternoon” or “11am”
- DURATION – time interval indicator such as “six weeks” or “last 45 minutes”
- AIRPORT – an airport name or code; SEATAC, LAX
- CITY – a city; Paris, Los Angeles
- COLOR – a color; blue, red, teal
- COUNTRY – a country; Canada, Italy, United States
- EMAIL – an email address; jane@myemail.com
- PHONE – a phone number; 800-555-1212, +66 11-222-3344
- POSTAL_CODE – United States postal code; 10001
- SET – a set of temporal indicators (series/repetitions) such as “every hour”
- STATE – a United States state; NY, Florida
- STREET – a United States descriptors for street names; Main St., 123 Main St. NE, 4420 East-West Highway Apt. 107
- URL – a URL; https://www.google.com/search?<param>
2 – Improving named entity recognition
In addition to recognizing many new entity types, our new model is a big improvement in entity recognition across the board.
Process for measuring named entity recognition models
Measuring the performance of entity recognition can be complicated. For the sake of building up our intuition, let’s consider an example from computer vision where you build a model to predict whether a picture is of an animal or not. When you test the model, there are two things to consider:
- Is the picture actually of an animal?
- Did the model predict the picture is of an animal?
With two yes/no questions, there are four possible outcomes:
- True Positives – the model correctly predicts the positive outcome; that a picture of a dog is an animal.
- True Negatives – the model correctly predicts the negative outcome; that a picture of a car tire is not an animal.
- False Positives – the model incorrectly predicts the positive outcome; that a picture of a stuffed bear is an animal.
- False Negative – the model incorrectly predicts the negative outcome; that a picture of a cat is not an animal.
From those numbers you can calculate the precision and recall. Precision is a measure of how likely the model’s predictions are to be correct: the true positives divided by the number of total predictions (true positives + false positives). Recall is a measure of how likely the model is to make a prediction when a positive prediction is possible: the true positives divided by the total positives (true positives + false negatives).
In the animal-image classification example above:
- Precision describes: If the model says a picture is an animal, how likely is it that the picture is actually an animal
- Recall describes: If the picture is an animal, how likely is it that the model predicts it is an animal
Once you have precision and recall, you combine them to produce an F-score. You do this by taking the harmonic mean. This can be weighted to favor one input over another, but we balance equally, which is known as the F1 score.
Turning back to entity recognition, we calculate precision by measuring the number of times a predicted entity was indeed a member of that class. For example, if our model labeled “Boston,” “Portland,” “Seattle,” and “Pepperoni” as a City, it would have precision of 0.75. We calculate recall by looking at a large sample of data and manually labeling all occurrences of City. If our model successfully labeled half of these as City, then our recall is 0.5. Using these measurements, we are able to show that our new global entity model significantly improves performance.
Doubling performance with our new model
We created a test set with 708 human-annotated messages from actual data to evaluate our new model and found it improved F1 from 42% to 89% — doubling performance. Here are the actual results per entity type. “Support” is the number of examples of that entity type in the test set.
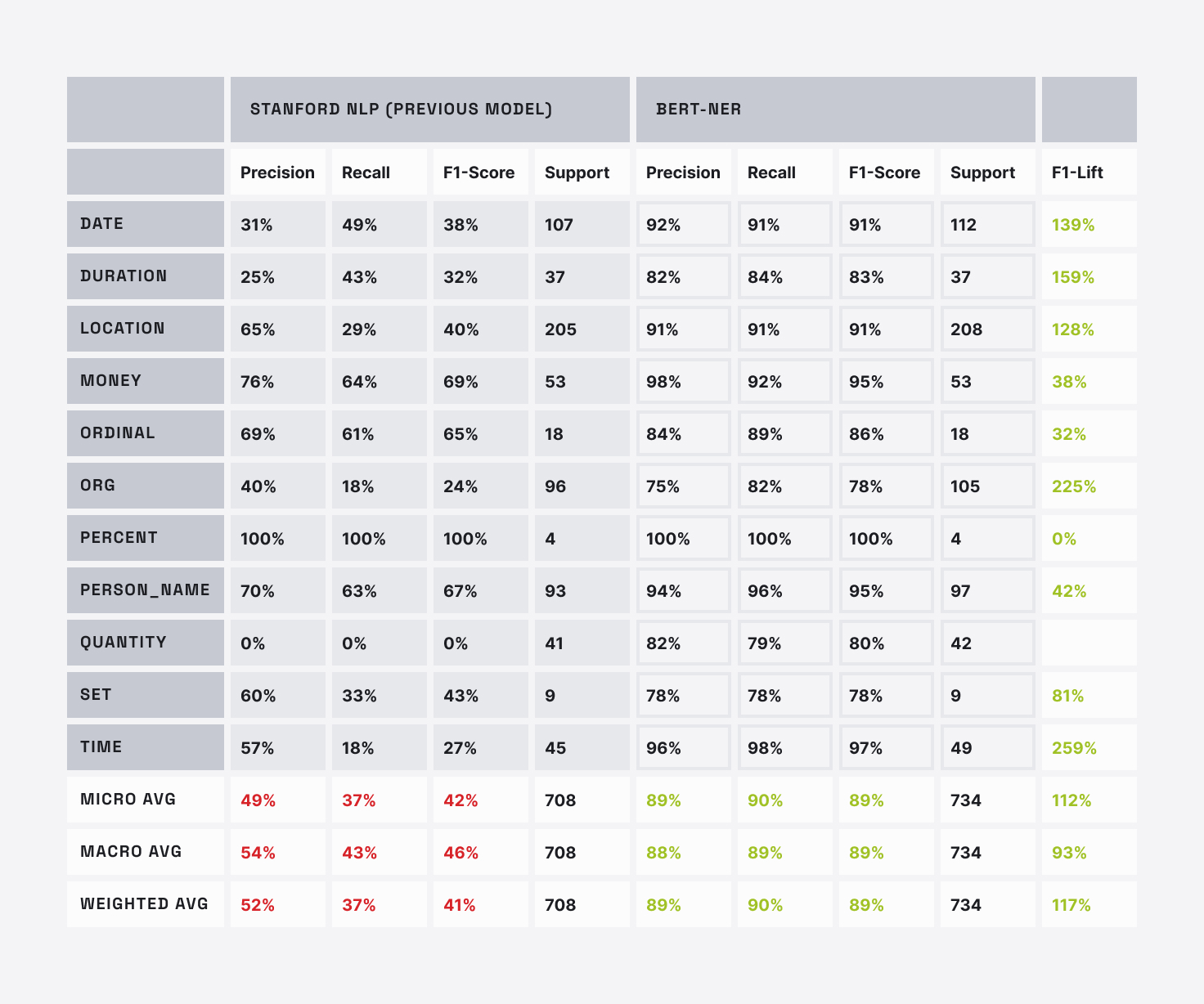
Those numbers are remarkable, so let’s consider what they mean
Precision and recall are often in tension. You can generally improve one at the cost of the other. In the animal-image classification example, you can increase recall — the percent of animal images the model recognizes — by setting a lower threshold for declaring an image to be an animal, but you’ll get more false positives, and this hurts precision. Likewise, you can increase precision — the probability that a recognized animal is correct — by setting a higher threshold for declaring an image to be an animal, but you’ll get more false negatives, and this hurts recall.
Precision in the new global entity model is significantly better than the old model. As one example, the old model had a low precision for dates — 31% — meaning that many recognized dates were incorrect. The new model’s precision is 92%. When the new model says something is a date, it is almost three times as likely that it is correct. This results from the BERT model process being better in general, and also our significant effort at providing more and better training data for the model to learn from. LivePerson taxonomists used data from billions of messages to assemble the best, most representative phrases for each entity type.
Recall in the new model is also significantly improved. So unlike the example with recognizing animals, we were able to improve both precision and recall. Looking at DATE again, the new model’s 91% recall almost doubles the old model’s 49%. Again, the taxonomy team’s work to discover a broader range of training data was key here: The BERT model is able to leverage better training data to discover more entity edge cases.
We found many remarkable examples of the new model’s performance, for example:
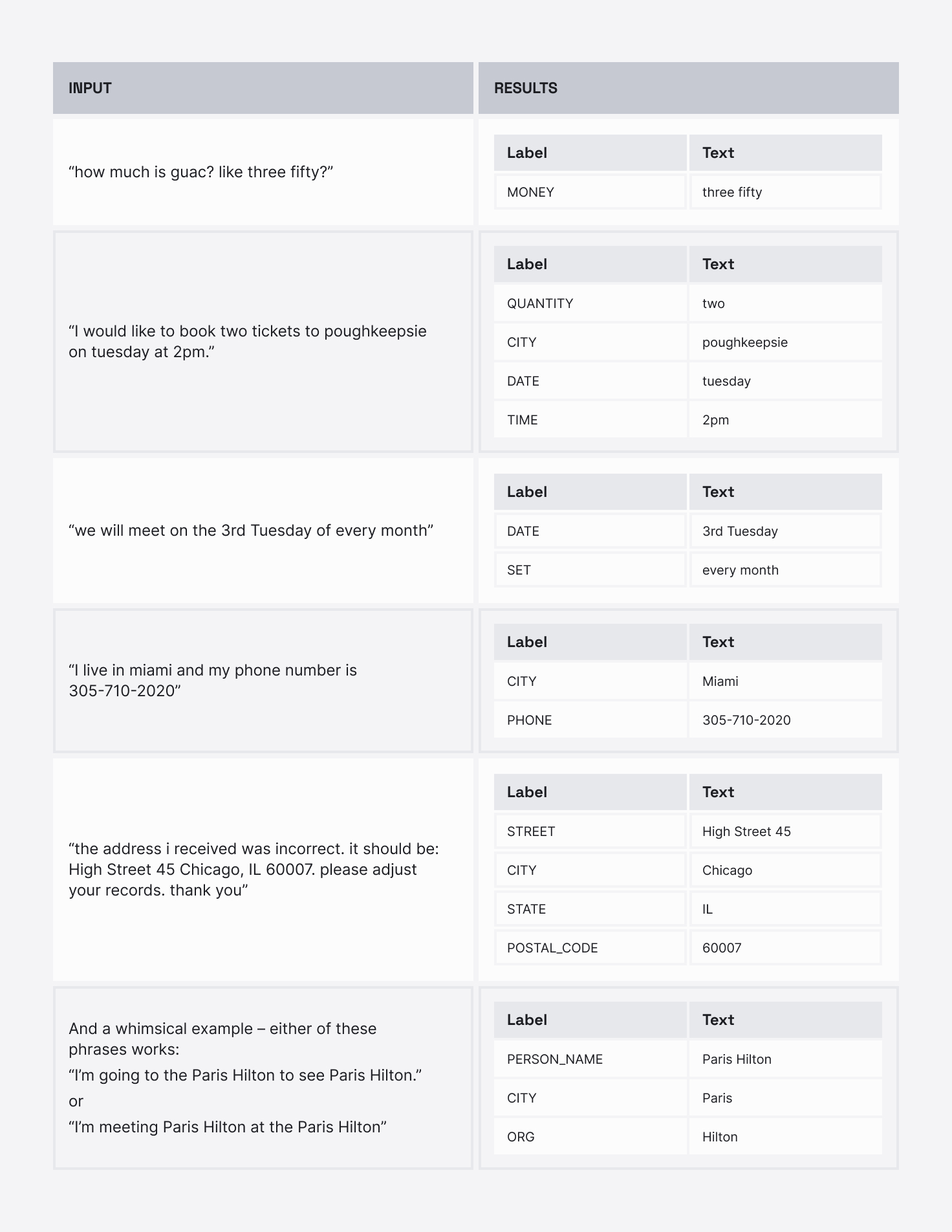
That last example emphasizes how the new model leverages context: Either way you phrase the sentence, it understands “Paris Hilton” as a person, and “Paris” as a city and “Hilton” as an organization.
Using entities to create more human experiences now and in the future
We’re deploying the new model now in coordination with our brand partners. Our goals are to improve the number of entity recognition events, the number of entity types recognized, and the intelligence of entity handling. To achieve those goals, we’re continuing to improve precision and recall, adding new entity types, and improving how brands are able to work with entities.
For example, LivePerson bots support slot filling. You create an interaction in a bot to collect the entity information (entity extraction), and add a rule to put the entity into a slot variable. If the entity has already been recognized in a consumer utterance, it is placed into the slot variable automatically, without displaying the interaction. Once you have the entity in a slot variable, you can control your bot’s flow based on the value and use it in responses to the consumer.
As shown above, the new global entities model is a huge step forward toward our goal of helping brands create better, richer conversational experiences for their customers at scale.