
article
Extending research in the field on entity linking in open-domain dialogue
Meet the first large-scale corpus of open-domain dialogues, helping chatbots understand consumers better than ever

November 15, 2022 • 11 minutes

LivePerson continues to promote the study and partnership between research and business institutions to drive innovation in the Conversational AI space through relationships with AI researchers. One such relationship is LivePerson’s partnership with the University of California, Santa Cruz (UCSC), where we have supported Ph.D fellowships as part of our ongoing collaboration with the Natural Language and Dialogue Systems Lab (NLDSL). We also support their natural language processing (NLP) master’s degree program through active participation on the Industry Advisory Board.
These kinds of research partnerships enable LivePerson data scientists to expand their vision for the future of Conversational AI, which ultimately benefits brands and consumers alike with better, more useful AI systems. Entity linking is one field that has profited from these research partnerships lately.
What is entity linking?
Entity linking in dialogue is the task of mapping entity mentions in utterances to a target knowledge base, that is, to make them concrete. For instance, if you were to hear someone say “I like Anaconda!” out of the blue, you would not immediately know whether this is referring to the Nicki Minaj song, the 1997 film, the city in Montana, or the software without contextual or co-textual clues such as familiarity with the speaker and their tastes or a sense of the recent conversations that they may have participated in.
Computers, of course, are limited in their ability to use/apply knowledge of this nature and are restricted to using only the adjacent context to help them make these determinations. And entity linking is still a new and fruitful field of research in natural language processing (NLP). For this reason, in partnership with UCSC, we have released the OpenEL corpus, which is an entity-rich corpus (a collection of written texts) that is human annotated with entity spans mapped to Wikidata IDs. In doing this, we hope to extend research in the field on entity linking in open domain dialogue.
The following is a summary of a conference paper that resulted from our UCSC partnership. Submitted by Leanne Rolston and Beth Ann Hockey alongside Wen Cui and Marilyn Walker of UCSC, the paper, “OpenEL: An Annotated Corpus for Entity Linking and Discourse in Open Domain Dialogue,” was presented at the 13th Conference on Language Resources and Evaluation (LREC) in June 2022, in Marseille, France. Aside from the authors, this paper would not have been possible without the help of the Conversation Management Science Taxonomy team (Dalia Levine, Julianne Marzulla, Emily Strouse, Daniel Gilliam, and Kurt Staufenburg) who provided the human judgements on the span annotation and entity mapping that makes this corpus so rich.
Named entity recognition (NER), named entity linking (NEL), and discourse modeling (DM) are crucial aspects of natural language understanding (NLU) for open-domain dialogue systems, such as AI chatbots or socialbots. Unlike task-oriented dialogue systems, open-domain systems need to be able to converse on any topic, with the concomitant challenge of handling a much wider variety of named entities. NEL provides grounding of the named entities in a knowledge base (KB) by assigning a knowledge-base ID to each named entity mention and anaphoric reference.
The following annotated conversation from the Comedy domain in the EDINA corpus illustrates NEL on definite referring expressions and anaphora. Definite referring expressions are highlighted in blue while anaphoric expressions are highlighted in orange.

NEL in general is challenging due to name variations. A named entity may have several surface forms, such as partial names, aliases, and abbreviations. Organizations may be referred to by their full name or by an abbreviation. NEL in open-domain systems is inherently more challenging due to the open-ended nature of possible topics, and the fact that utterances tend to be short, informal and ambiguous, which requires the NEL system to leverage the dialogue context and entity information, such as its type, alias, and description.
Typically entity linking is a three-stage pipeline system that performs mention detection (MD), candidate generation, and entity disambiguation (ED). In the question/answer pair, the question, “You psyched about this coming NFL season?” is answered with, “Oh yeah. Can’t wait to see my Giants in action.” The reference to the NFL helps determine that the entity mention Giants in the response refers to the New York Giants (a football team) instead of the San Francisco Giants (a baseball team):
- Mention detection identifies the span of the surface form Giants.
- Then candidate generation takes the mention Giants and generates plausible candidate entities from the knowledge base (KB), such as New York Giants, San Francisco Giants, Yomiuri Giants, Giants (the album), and Giants (the comic book).
- Finally, entity disambiguation utilizes a trained ranker that takes the mention and the list of candidates and uses contextual information to rank the candidates.
The desired result, the New York Giants, should then be promoted to the top of the candidate entity list.
Our experiments
Prior work has shown that dialogue context and entity discourse improve model performance in NER and NEL related tasks. Therefore, we test selected NEL systems in three settings in terms of how much context the system has access to:
- UTTERANCE: The input to each system is only one utterance, therefore, it does not have access to any dialogue context.
- DIALOGUE: Unlike performing NEL on written articles or news, a dialogue system has access only to previous context but not any content that comes later. To replicate this situation, the input to each system is all previous dialogue context and the utterance itself.
- DISCOURSE: Similar to the DIALOGUE setting, the system has access to all previous dialogue context. Additionally, we resolve anaphoras by substituting them with their actual entity mentions. In the example above, this represents replacing That with The Other Woman, their with Cameron Diaz and Leslie Mann, etc.
Then, considering publicly available models that do not require extra fine-tuning steps or modifications, we evaluate several well-known traditional machine learning (ML) and deep learning (DL) based NEL models on our corpus OpenEL and compare their results.
- DBpedia Spotlight is a well-established NEL tool that represents the target knowledge base DBpedia in a Vector Space Model. It then links mention by cosine similarity between the context vector of the mention and the candidate in the knowledge base. We set the confidence threshold to 0.5 as suggested in the documentation. Since Spotlight links to DBpedia KB, we mapped DBpedia entities to Wikidata IDs by sending SPARQL queries to DBpedia and manually creating the mapping if the query fails.
- WAT is another prominent NEL tool based on TagMe and links to Wikipedia entities. A support vector machine (SVM) is trained with hand-crafted features for mention detection (MD), while a voting scheme based on PageRank is proposed for entity disambiguation (ED). It also employs an additional annotation pruning step that is trained on another SVM. We used its web service together with the Wikipedia API to obtain the Wikidata ID from the Wikipedia entity. The confidence threshold of 0.3 achieved the best F1 on our tests and therefore were used throughout the experiments.
- REL is a pipeline system that uses Flair for NER and a multi-layer perceptron (MLP) with a max-margin loss for ED. It is trained on AIDA with pre-trained word embedding and features such as context similarity, coherence measures, and mention relations. We used their API service for testing. The confidence threshold was tuned and set to be 0.2 for all the experiments.
- Flair+BLINK BLINK is a zero-shot Transformer based ED system that is fine-tuned on BERT to encode mentions, context and entity description with a linear layer for scoring. It achieved state of the art performance on the benchmark dataset TAC-KBP2010. To perform end-to-end NEL, we employed BLINK with Flair for NER.
Micro-averaged precision, recall, and F1-measure are commonly used to evaluate NEL systems. We compare the predicted outputs to the ground-truth labels using both weak and strong matching approaches. Strong matching requires exact matching of text span boundaries and a correct Wikidata ID, while weak matching accounts for partial span overlap.
Results
We ran baseline systems using all the conversations in OpenEL. The following table provides NEL evaluation results in UTTERANCE (UTT.), DIALOGUE (DIA.), and DISCOURSE (DIS.) settings. Numbers in parentheses are the relative improvement compared to the UTTERANCE setting within the same metric. And numbers tagged with † are not statistically significant (p-value >0.05 with approximate randomization tests) compared to the UTTERANCE setting. The best F1-score evaluated using different settings and matching methods are highlighted in bold. Models indicated by * are deep learning (DL) based models.
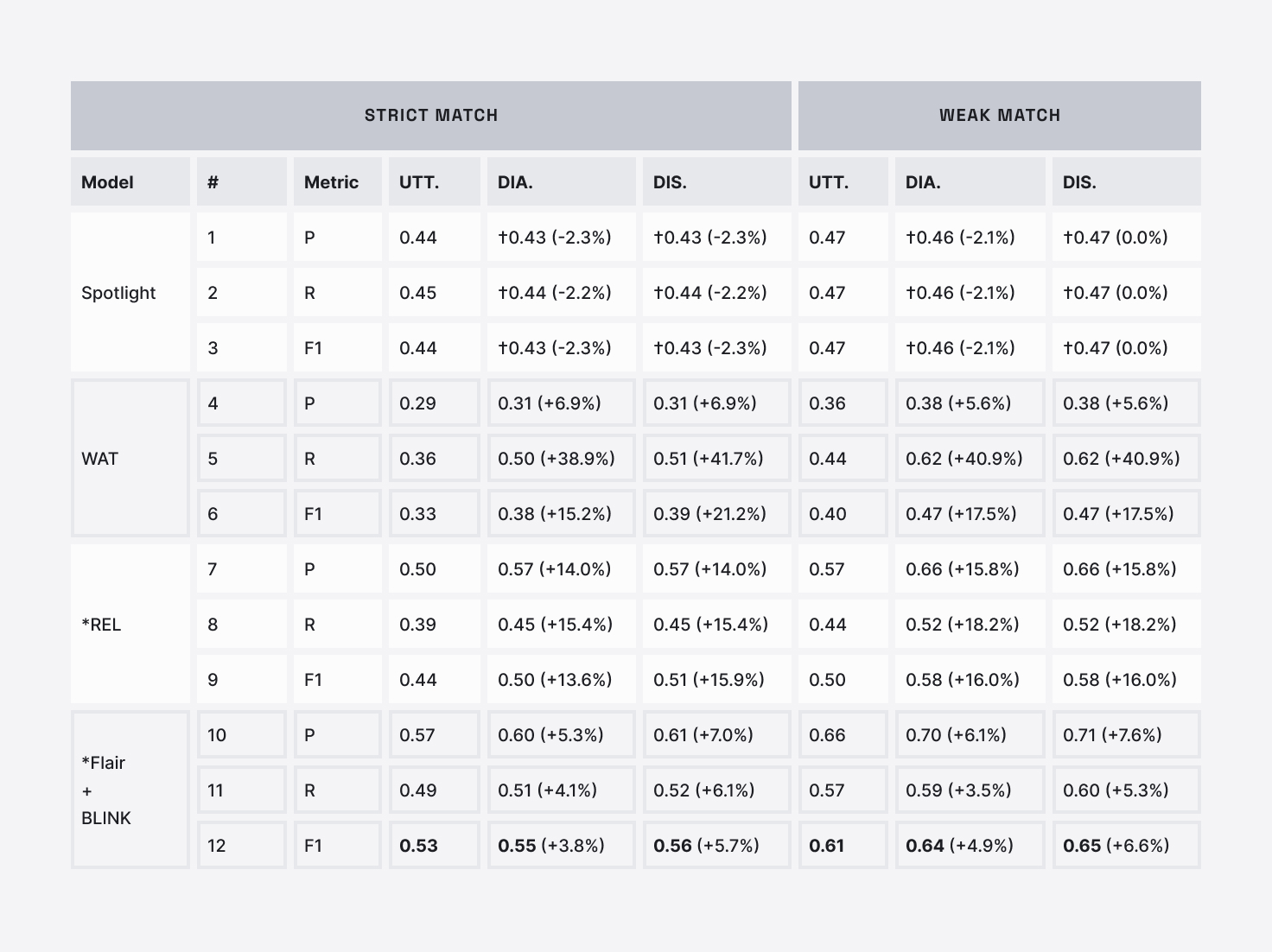
We can see that the Transformer-based system Flair+BLINK performs the best across all metrics (Row 12) with the highest 0.56 F1-score for strict match and 0.65 F1-score for weak match. It is pre-trained on massive data and captures more sophisticated feature representations of NEL. However, there still remains a big performance gap compared to its almost state of the art performance on other NEL benchmarks.
The results also suggest the effectiveness of dialogue context in the decision making process of NEL systems. All systems except for Spotlight have a substantial performance gain (numbers in parenthesis) that varies from 3.8% to 17.5% in terms of F1-score by feeding the previous dialogue. Another performance boost up to 6% is observed by resolving anaphoras in the dialogue context. WAT has a relative ∼40% improvement in recall (Row 5) benefiting from its feature of exploiting context surrounding the mention. REL and Flair+BLINK both use Flair for NER, whereas REL has a higher relative F1-score improvement in both DIALOGUE and DISCOURSE settings (Row 9 and 12).
Since REL explicitly represents mention relations as latent variables in the entity disambiguation stage, having access to dialogue context results in a better mention representation as well as linking. On the other hand, Flair+BLINK benefits from its architecture that captures long-distance dependency in language. In contrast, Spotlight shows slight F1-score decline in both DIALOGUE and DISCOURSE settings (Row 3) due to limitations of cosine similarity.
Following are examples of NEL system inputs and outputs on the last utterances in the UTTERANCE (UTT.), DIALOGUE (DIA.), and DISCOURSE (DIS.) settings. Ground-truth anaphoras are replaced with their mentions in the DISCOURSE setting (highlighted in orange). The system output is in the format of (mention, entity title, Wikidata ID). Correct outputs are indicated with a checkmark. For illustration purposes, we assign A and B to indicate turn exchanges, however, they are not a part of the input. Also the dialogue is shortened due to space limitation.

This shows that adding the context referring to Nicki Minaj helps Flair + BLINK successfully link “Anaconda” to the correct reference (the song), while the absence of context links the term to a gun. In the second example, without any context, WAT links “Posey” to a county. In the DIALOGUE setting, by giving dialogue context, the system links it to a basketball player, James Posey. Finally, in the DISCOURSE setting where references are substituted for anaphoras, it is linked to the correct baseball player, Buster Posey.
In open-domain conversations, the topics human participants can talk about are unrestricted. Therefore it requires the NEL systems to be able to perform linking for entities in any topic domain. To evaluate the topic coverage, we compare the F1-score on all 12 topics in the DISCOURSE setting. Scores are calculated based on weak match. The support of gold entities for each topic are in the parenthesis on the label of X-axis. And topics are sorted in descending order in terms of support.
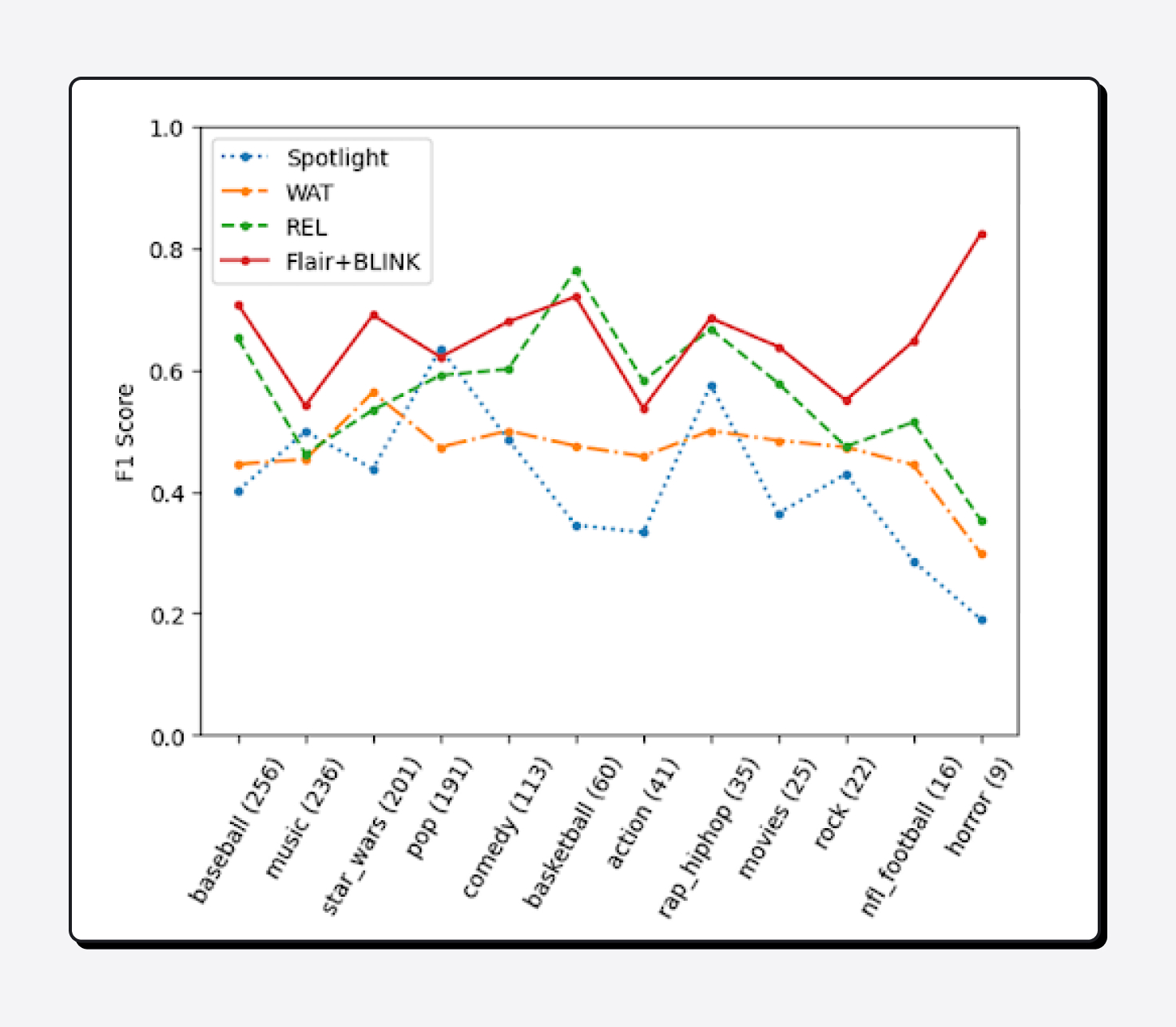
We see that the performance of each system varies by topic. WAT and Flair+BLINK systems have relatively consistent performance across all topics. Both Spotlight and REL have weaknesses in the NFL football topic. The overall best model, Flair+BLINK, has its lowest F1-scores on the music, rock, and action movies topics, which may be due to the difficulty recognizing album names, song names, or movie names since they tend to be highly ambiguous.
Conclusion
We present and make publicly available the OpenEL corpus, the first large-scale corpus of open-domain dialogues annotated for NEL and anaphora with high annotator agreement.
We tested and compared existing NEL systems, including machine learning and deep learning based methods, on our corpus. We demonstrated the effectiveness of using dialogue context and anaphora resolution in open-domain NEL. We also showed the existing NEL systems with a performance gap between open-domain dialogues and human performance, which highlights the challenges of NEL in such settings. We plan to extend our corpus by annotating more conversations from other topics in EDINA and other conversational datasets. We envision our corpus as a good source of studying challenging problems, such as entity linking, anaphora resolution, and knowledge-grounded dialogue generations, in the context of open-domain dialogue systems.
Read the full paper including all bibliographic references at the LREC Conference source. Learn more about LivePerson data science and research partnerships here, or join us at an upcoming conference sponsorship or event.