
article
Introspective Conversational AI: Virtual agents that notice their mistakes

March 04, 2022 • 6 minutes

In 1950, Alan Turing defined the “Turing Test” to evaluate whether a machine is as intelligent as a human. Turing realized that the pinnacle of human cognition is the ability to comprehend and produce novel utterances, with the goal of achieving shared understanding (intersubjectivity) and forward movement in the conversation (progressivity). Therefore, to pass the Turing Test, a dialog system must convince its social partner that it is human through conversation. The idea is that if a dialog system (otherwise known as AI chatbots or virtual agents) can use language competently, it must be as smart as a person.
But it’s not that easy
Since 1950, a lot has changed. The first chatbot – a dialog system that uses messages to communicate – was invented in 1966. The internet’s “official birthday” is 1983, and the first smartphone was created in 1992. But despite incredible advances in technology, natural language processing, and psycholinguistics (the study of how people use and comprehend language), commercial dialog systems still fail the Turing Test. They don’t even come close. Sometimes, home devices may appear virtually human. But other times, they fail in ways humans never do, instantly reducing them to flat, mechanical things. So, how can we create dialog systems that exhibit intelligent behavior as Turing envisioned?
To help answer this question, LivePerson asked another one – how do people get better at communicating?
Psychology research tells us that people self-monitor (Snyder, 1974), or introspect on their social behaviors and change what they say accordingly. For example, a self-monitor adjusts their social behaviors to match the people around them. In the workplace, self-monitors “get along” and “get ahead” – they’re better liked and promoted more often (e.g. Day & Schleicher, 2006). At the core of this behavior is an ability to evaluate how their communication impacts the way they are perceived by others.
How we are creating self-monitoring virtual agents
LivePerson decided to implement self-monitoring in their dialog systems. The next challenge was to determine which behaviors should be monitored. The selected behaviors would have to be common in dialog systems and indicate problems that could be resolved by adjusting the system. After much consideration, LivePerson decided to measure the features of conversations that people perceive as most important.
The most fundamental features of any successful conversation, from task-oriented conversations with customer service agents to casual conversations with a friend, are intersubjectivity (Schegloff, 1992) and progressivity (Stivers & Robinson, 2006):
- Intersubjectivity – when everyone believes that everyone understands everyone else.
- Progressivity – when speakers continue the action of a conversation by answering questions or completing tasks.
Good conversations are both progressive and intersubjective, and consumers are painfully aware of when one (or both) of these features are missing. Take for example the following conversation:
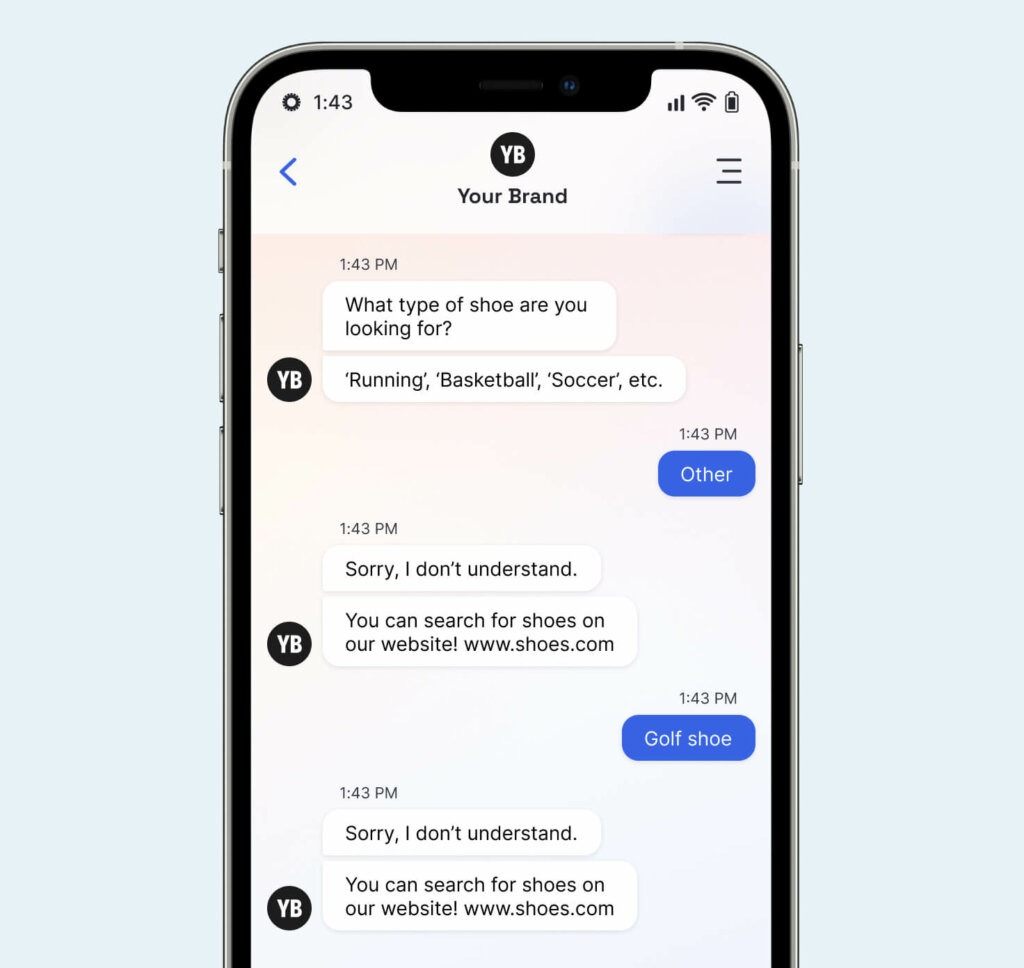
Once the consumer says something unexpected (“other”), all virtual agent progress stops and there is no hint of understanding. And yet, traditional performance metrics would not identify this conversation as negative. Sentiment Analysis relies on the consumer’s text, which in this case expresses no emotion. By convention, this conversation was also “contained,” because the consumer left before they were transferred. Most companies would not collect CSAT for this conversation because the conversation wasn’t completed. Finally, while NLU would produce a low confidence score for the second half of this conversation, this information alone cannot determine how a dialog system handles the uncertainty. Effectively, the dialog systems that brands are deploying become black boxes that are hard to improve and result in poor customer experiences.
As a result, LivePerson developed what we call conversation quality indicators (Higgins et al., in review), or CQIs for short, which measure intersubjectivity and progressivity. These CQIs are designed to be actionable, meaning they suggest routes for improvement.
Progressivity-focused CQIs
These indicators tell dialog systems if they make progress, are stuck, or are moving backwards. When dialog systems Gather Information, they get closer to addressing a consumer’s intent. In the conversation above, the dialog system / virtual agent pushes the conversation forward by asking targeted questions. In contrast, dialog systems can get stuck in a loop if they repeatedly Reprompt (turns 6, 8) the consumer. Finally, if a dialog system asks a few questions and then determines it is Unable to Assist, or Unable to Transfer, the consumer ends up back where they started – only more frustrated.
Progressivity-focused CQIs mark a huge improvement over other measures of efficiency, like the number of turns to resolution. While there are correlations between resolution time and customer experience, a more competent dialog agent may actually spend more time with a consumer. For example, a dialog agent that proactively suggests items to the consumer may produce more turns than one that simply retrieves an item the consumer requests. However, as long as each turn adds new information and responds appropriately to the consumer, LivePerson virtual agents will not be penalized for longer conversations.
Intersubjectivity-focused CQIs
These indicators identify points in a conversation where the dialog agent fails to understand the consumer. There are two types of intersubjectivity problems, each with a different effect on the consumer. First, the dialog agent may notice the problem and request help from the customer, producing a Reprompt. Unsuccessful reprompts, where consumers get stuck in the conversation, are very frustrating, but a single reprompt that tells the consumer what to say is less so.
An arguably worse problem is when the dialog agent does not notice the lapse in intersubjectivity, and Misunderstands the consumer. They may answer the wrong question or resolve the wrong intent, with no way for the consumer to correct them.
More conversational quality indicators to come
As research has progressed, CQIs have been continuously discovered and refined. LivePerson plans to design CQIs that account for additional social goals, like demonstrating competence or social closeness. We also plan to develop patterns of problems that represent problematic sequences of turns within a conversation. With each iteration, CQIs provide more comprehensive insights into performance and inch dialog systems / virtual agents closer to human agents.
The future is smart…and introspective
Most dialog systems can’t tell when they’re failing, let alone adjust their strategies in the moment or propose solutions. Introspection will make all of this possible. Introspective dialog agents will react flexibly to customer behavior and act as their own tuners to “get along” and “get ahead.” One day, they will perform just as well – if not better – than human agents. If we scale dialog systems to billions of conversations a year, we need these types of feedback systems to ensure customers’ experiences are high quality.