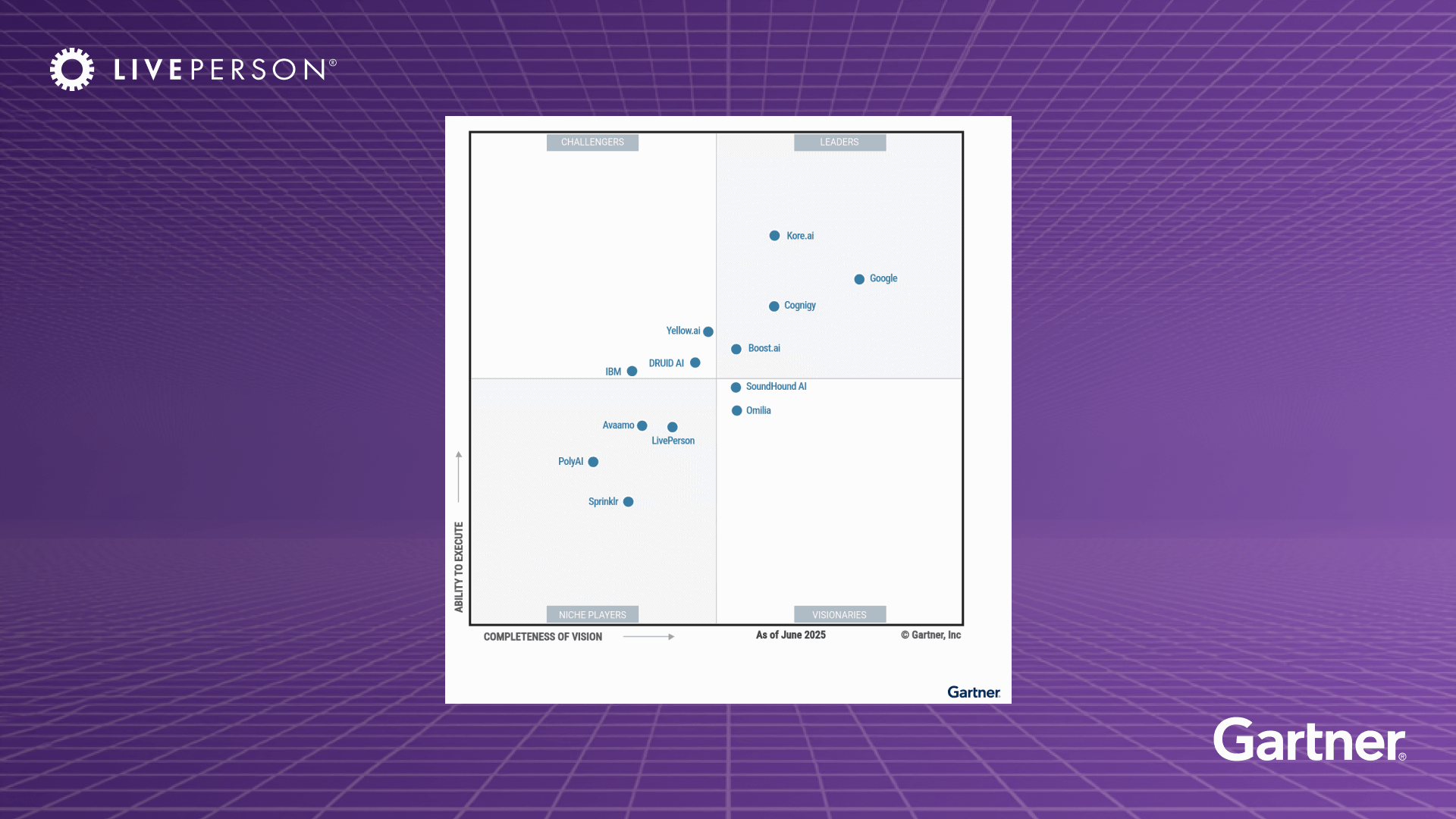
article
Experimenting in production is the new CX technical debt

May 01, 2026 • 6 minutes

In 2026, AI technical debt doesn’t look like bad code. It looks like unpredictable behavior in live customer conversations.
Discovering AI hallucinations and brand-damaging failures through live customer complaints is not a risk management strategy. For too many enterprises in 2026, it’s the default one.
The reasons are understandable. Deploying AI is hard, testing it is harder, and the pressure to move quickly is real. But the cost of learning in public has shifted. What was once a manageable inconvenience is now a brand liability, a compliance risk, and increasingly, the reason AI deployments stall before they ever reach their potential.
The debt is behavioral, not technical
Technical debt is well understood. You move quickly, accept shortcuts, and defer cleanup, accumulating a backlog of outdated dependencies, architectural decisions made under pressure, and code that works until it doesn’t. The debt lives in the codebase, which means it’s visible, traceable, and fixable.
Technical debt lives in systems. Behavioral debt lives in customer conversations.
When AI agents are deployed before their behavior is fully evaluated, the failures don’t stay in the system. They occur in customer interactions, in real time, with real consequences. An agent that misquotes policy, misreads intent, or escalates at the wrong moment doesn’t give you a chance to intervene before the damage is done. And unlike a buggy feature, a broken customer experience can’t always be patched after the fact.
What makes behavioral debt structurally harder to manage is that it’s invisible until it surfaces. It doesn’t accumulate in a codebase where someone might notice it. It accumulates in live interactions, in edge cases that only appear under real conditions, in failure modes that no internal test ever replicated. By the time it becomes visible, it has already cost something.
This is the new form of AI technical debt. And unlike traditional debt, it compounds externally.
Why production became the lab
The practice of discovering failure in production has a reasonable origin. For systems with deterministic logic and bounded outputs, late-stage discovery was an acceptable trade-off. The cost of catching an edge case in production was low, and the cost of delaying deployment to find it earlier was higher, so brands made a rational choice and moved on.
Generative AI inverts this calculus entirely.
The properties that make GenAI capable, including contextual reasoning, adaptive response generation, and behavior that shifts with input, also make its failure modes non-deterministic in ways that matter. A system that performs correctly across a thousand test scenarios can still produce an unexpected output in scenario 1,001, not because the model is broken, but because real customers introduce complexity that synthetic tests don’t fully capture.
More thorough testing of the same kind won’t close this gap because it’s a structural property of the technology. Treating production as the final test environment leaves brands without a reliable way to prevent failures before they reach customers.
The governance gap
Mature AI governance councils in regulated enterprises are arriving at this conclusion independently. They are increasingly blocking AI deployments, and the reason is specific: they need evidence.
Not a demo. Not a performance report. Not an assurance from the team that built the system. They need audit-ready proof that the AI agent was evaluated against realistic scenarios before deployment, that edge cases were surfaced and addressed, and that the system’s behavior under stress aligns with declared policy, regulatory obligations, and escalation design.
Most pre-production testing processes do not produce this evidence. They are too narrow in scope, too disconnected from AI governance requirements, and too dependent on manual effort to scale. They may produce test results, but not defensible attestations. The result is a deployment that stalls at the threshold between pilot and production because the brand cannot prove the system is ready.
Brands have capable models. What many lack is a systematic way to demonstrate readiness before customer exposure.
What readiness actually requires
AI readiness is the organizational capacity to deploy AI responsibly at scale. It requires the processes, tooling, and evidence structures that allow a brand to validate behavior before deployment, observe it continuously during operation, and defend it under external scrutiny.
In practice, that means being able to produce:
- Scenario coverage reports tied to defined customer personas
- Escalation pathway validation against policy
- Failure-rate analysis across edge-case interactions
- Audit trails linking observed behavior to governance criteria
Without a systematic approach, the pattern is consistent: learning happens in production, remediation is reactive, and executive confidence rests on trust rather than proof. Governance remains procedural rather than operational.
A brand that has closed this gap can do several things that most cannot. It can conduct structured AI agent stress-testing against synthetic personas and complex scenarios before those agents interact with real customers. It can surface edge cases, logic failures, and intent mismatches in a controlled environment where fixing them is fast and low-cost. It can produce the attestations and audit trails that governance councils require, on a timeline that does not derail the deployment roadmap.
Simulation as the missing layer
The mechanism that makes this possible is simulation: controlled, repeatable AI simulation and evaluation of behavior against defined scenarios and personas before any customer exposure.
Simulation operates at the level of conversation, not unit logic. It models realistic customer behavior, including adversarial, ambiguous, and emotionally complex interactions, and evaluates AI agent responses against explicit governance criteria. When an agent fails a simulated scenario, the failure is specific, diagnosable, and correctable before it reaches production. This is the foundation of a rigorous TEVV (Testing, Evaluation, Verification, and Validation) practice applied before any customer is exposed to the system.
This is the evaluation layer Syntrix® was built to provide. A controlled environment in which AI agent and live agent behavior can be made observable, accountable, and predictable before either interacts with a real customer. It provides the evaluation layer that makes a capable model deployable at enterprise scale.
The outcomes are direct and, for brands used to treating production as the lab, somewhat counterintuitive. AI agents that have been evaluated against realistic scenarios perform more predictably, escalating to live agents at the right moments and handling edge cases that untested agents fail on.
In enterprise deployments, this approach has reduced agent ramp time and delivered measurable onboarding cost savings per agent. The broader finding is that investing in simulation before deployment actually shortens the overall deployment lifecycle, because certifying readiness in a controlled environment removes the cycles of discovery, remediation, and re-review that slow production deployments down.
The enterprise moves faster because it stops learning in public. It moves from ambiguous AI to predictable AI.
The cost of delay
Conversational AI is entering an accountability phase. The ability to predict, explain, and defend AI behavior is now the primary constraint on deployment for enterprises operating in regulated environments, and increasingly for those that are not.
Brands that treat production as the lab are accumulating behavioral debt at a rate that isn’t visible in the current period. It becomes visible when a deployment fails publicly, when a regulatory audit surfaces undocumented decision paths, or when an AI governance council demands evidence that does not exist.
Brands scaling AI with confidence in 2026 took the time to validate their systems before exposing them to customers, knowing that discipline compounds over time. Because the defining question now isn’t whether your AI works, but whether it’s ready before customers are the ones who discover it isn’t.
Syntrix is a simulation and evaluation platform that contact center and CX leaders use to validate AI agents and certify live agent readiness before either interacts with a real customer. Experience how Syntrix helps enterprises move from ambiguous AI to predictable AI.